Your AI Agents Will Reflect Your Org Chart (Whether or Not You Want Them To)
Most writing about AI in enterprise assumes a greenfield project ecosystem. Clean data, willing teams, clear ownership. You read these posts and think: sure, that would work if I were building a company from scratch.
But not everyone is building from scratch. If you’re trying to build things at an existing company, you’re working with what Conway’s Law has been describing since 1967. And AI doesn’t change that. It makes it more visible, faster, and harder to ignore.
“Any organization that designs a system will produce a design whose structure is a copy of the organization’s communication structure.” – Melvin Conway, 1967
In plain English: your software ends up looking like your org chart. If your teams are siloed, your systems will be siloed. If your teams don’t communicate, your systems won’t either.
If you want to know what this looks like in practice, you’ve probably already seen it:
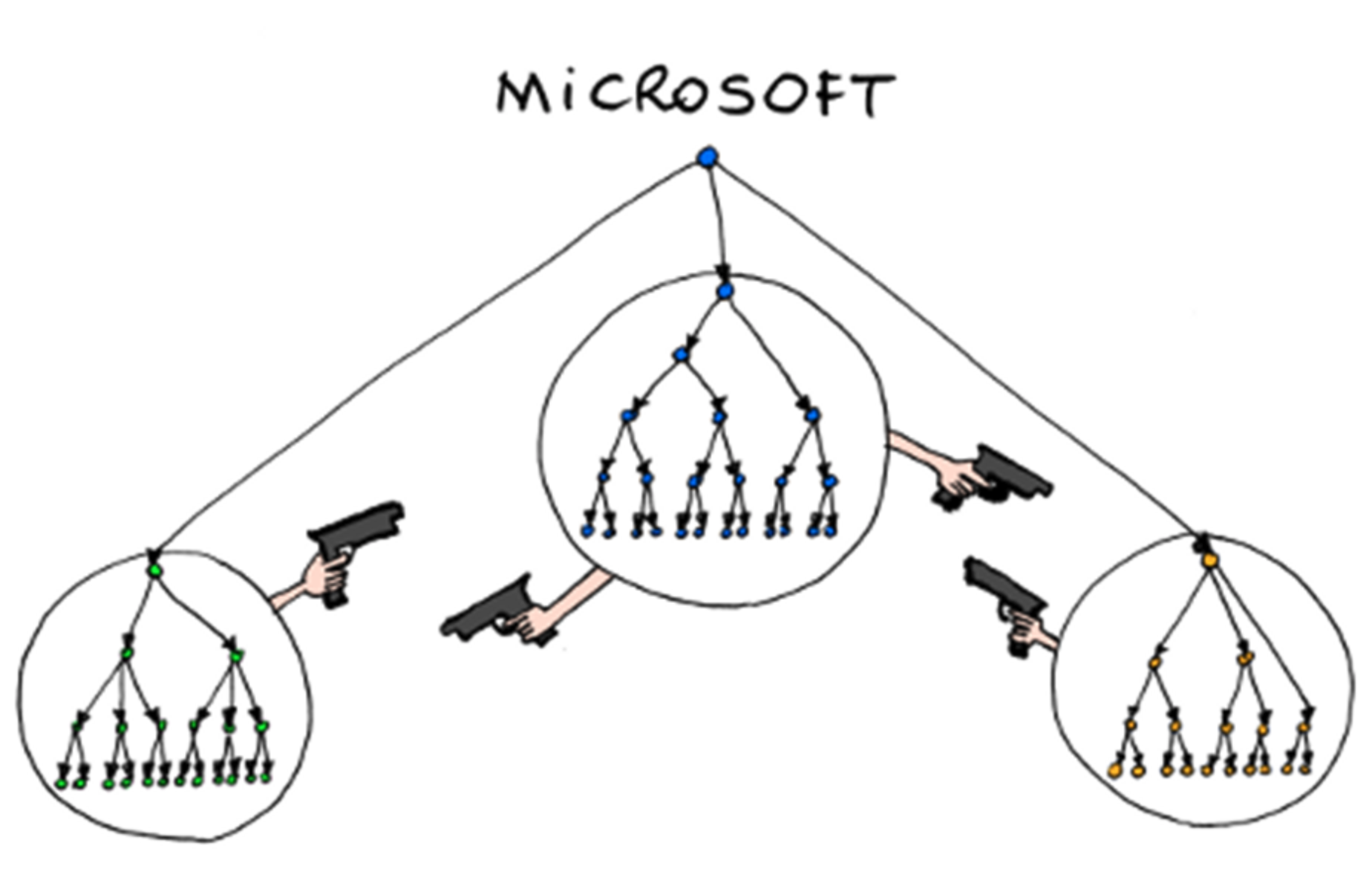 Source: Bonkers World
Source: Bonkers World
Toby Elwin put it well earlier this year: “an enterprise cannot adopt AI faster than it can align decision rights, language, and accountability.” That’s the theory. Here’s what it actually looks like when you try to deploy AI agents inside a large company.
What Conway’s Law actually means in practice
You already know the textbook definition. But here’s what it looks like on a Tuesday afternoon.
If your platform team and your analytics team don’t talk to each other, your data warehouse will have two overlapping schemas that don’t agree on what a “customer” is. If the security team reports to a different VP than the engineering team, your deployment pipeline will have a manual approval step that adds two weeks to every release. And if your regional offices operate semi-autonomously, your CRM will have three different ways of tracking the same deal.
None of these are technology problems. They’re org chart problems that got encoded in technology. And they’ve been accumulating for years. Sometimes decades.
The standard advice is to fix the org chart first. Good luck with that. Reorgs take years, cost political capital, and usually create new problems while barely solving the old ones. So in practice, most teams just build around the dysfunction. They write adapter code. They maintain spreadsheets that bridge two systems that should be one. They develop tribal knowledge about which database is the “real” one.
This is the environment your AI agent is about to inherit.
“If the architecture of the system and the architecture of the organization are at odds, the architecture of the organization wins.” – Ruth Malan
The database as org chart
As Joe Reis puts it: “When different departments or teams operate independently with limited communication, they often develop their own data models and systems, resulting in data silos.” And “every redundant or inconsistent piece of data slows down decision-making, hinders innovation, and erodes trust in the data itself.”
If you’ve looked at a large company’s data warehouse, you’ve seen this. The schema isn’t a data model. It’s an org chart.
You know what this looks like in practice. One team has clean, well-documented tables. Another team’s schema is a graveyard of quick fixes from three reorgs ago. And somewhere above both sits a corporate data layer that takes six months and a committee to change. Zhamak Dehghani built the entire Data Mesh paradigm on this observation, following “the seams of organizational units” because the centralized approach kept producing warehouses that looked exactly like the orgs that built them.
So what happens when you point an AI agent at one of these warehouses and ask it to answer questions about the business? The agent hits every one of those seams. A query fails because two teams define “customer” differently. A join breaks because a table was built as a quick fix during a reorg and never cleaned up. Access gets denied because a different part of the org controls that data and your project isn’t on their radar.
The agent isn’t navigating a database. It’s running into the same walls that every human in the organization already knows about, just faster.
And the constant push to consolidate everything into one governed layer? That’s rarely a technical decision. Centralizing data means centralizing control. The people pushing for it aren’t thinking about query performance. They’re thinking about who gets to decide what the numbers mean.
“Every data model is a political artifact. It reflects who had influence, what got prioritized, and what got ignored.” – Joe Reis
Tribal knowledge is the real architecture
Every large company has people whose real value is knowing how to navigate systems that aren’t documented. They know which CRM fields are reliable and which are garbage. They know that a “Stage 4” deal means something different depending on the region. They know which reports to trust and which ones quietly pull from a table that hasn’t been updated in months.
None of this is written down. It lives in people’s heads. And the people who hold it have very little reason to share it.
Now build an AI agent that queries the same systems and summarizes the answers in plain English. Suddenly, what used to require knowing the right person to ask is available to anyone.
The pushback will sound technical. “LLMs are bad at SQL.” But here’s what I’ve noticed: the people saying that aren’t testing LLMs on clean data. They’re testing them on the messy internal data that only they know how to query. And when the LLM struggles with it, they feel validated. Of course it can’t do what I do. Look how hard this is.
Research from The HR Digest found that 35% of employees are actively hoarding knowledge due to fears of being replaced by AI. That tracks with what I’ve seen. People who’ve spent years learning to navigate an undocumented mess take real pride in that skill. When an agent threatens to make it available to everyone, the reaction isn’t “great, less grunt work.” It’s “why would I automate myself out of a job?”
“It is difficult to get a man to understand something when his salary depends upon his not understanding it.” – Upton Sinclair
AmplefAI calls this the permission graph problem. In a pre-AI org, access to information is gated by people who know where things are and how to interpret them. When an agent automates that, the graph changes. Knowledge that required a specific person becomes available to anyone with a URL. The org chart says nothing changed. But the actual power structure shifted.
Shadow AI is just faster IT
Here’s the pattern I see in large companies. Someone builds a useful AI tool. It works. People start using it. It spreads through word of mouth.
Meanwhile, the official AI initiative is still in procurement. Or it shipped, but it’s slow, locked down, and missing the features people actually need. So two systems end up running in parallel: the one the org chart knows about, and the one people actually use.
This isn’t hypothetical. Over 80% of workers use unapproved AI tools at work, according to UpGuard’s 2025 Shadow AI report. Microsoft found that 71% of UK employees use unauthorized consumer AI tools on the job. And only 37% of organizations have any governance policies to deal with it.
The security folks will tell you this is a risk problem, and they’re right. IBM found that shadow AI breaches already account for 20% of all data breaches and cost $670K more on average. But it’s also a Conway’s Law problem. The official system mirrors the formal org: approved vendors, IT governance, formal data access policies. The shadow system mirrors the actual communication structure: where information really flows, where decisions get made, who people trust to build things that work.
The formal system and the shadow system are both doing exactly what Conway’s Law predicts. They’re just reflecting two different orgs. Leadership makes decisions based on one. The work actually happens in the other.
And here’s the tension: the builders get punished. Someone ships an internal AI tool that people actually use and love, and the response from the official org isn’t “great, let’s support this.” It’s “you didn’t go through the process.” The official system isn’t optimized for effectiveness. It’s optimized for control. So the people who are actually solving problems get told to stop, while the sanctioned app that went through 18 months of governance sits unused.
The real lesson
Most of the writing on Conway’s Law and AI is speculative. People theorize about what AI-dominated teams might look like, as if we’re designing from a blank page. We’re not. We’re deploying AI into organizations that have decades of accumulated structure, politics, and workarounds baked into every database schema and every deployment pipeline.
AI agents don’t liberate you from Conway’s Law. They’re subject to it. They inherit your org’s boundaries, your data’s politics, your team’s dysfunction. Maybe that changes someday, but right now, in the early days of deploying this stuff inside real companies, the org chart wins every time.
But that doesn’t mean you’re stuck.
The people who are actually shipping useful AI inside large companies aren’t waiting for the org to fix itself. They’re building. They’re copying patterns that work from industry, picking their tech stack, and making things that people actually want to use. Sometimes that means bending rules. Sometimes it means ignoring the committee that wants to spend six months on a strategy deck before anyone writes a line of code.
If you’re about to deploy AI agents inside a large org, here’s my advice: build things that are actually useful. Not things that look good in a slide deck. Not things that satisfy a governance checklist. Things that save someone 20 minutes on a Tuesday. That’s how adoption happens. Not from the top down, but from one useful tool that spreads because people like using it. You’ll need top-down support eventually, no question. But leadership almost never gets this right from the start. So build first, prove value, and let the support catch up.
And whatever you do, don’t let people who can’t build dictate what gets built.